Common Challenges of Knowledge Management and How to Overcome Them

Inside the article
Key Takeaways
- 84 percent of employees make decisions based on assumptions at least four times weekly because they cannot find answers that exist inside their own organizations.
- The most common KM failures are not technical. They are organizational: no ownership, poor adoption, and content that decays without anyone noticing.
- AI makes a good KM system better and a broken one worse. Fix the foundation before you layer in AI.
- Every unsolved KM challenge has a measurable cost: wasted time, repeated mistakes, slower decisions, and knowledge that walks out the door when people leave.
Summarise this blog for me
Too busy to read the full article? Get a quick summary in your preferred AI tool.
Introduction
Most organizations have some version of a knowledge management system. What they do not have is one that works consistently. According to Pryon, 47 percent of professionals spend one to five hours every day searching for specific information. That is not a storage problem. It is a strategy problem.
The challenges of knowledge management are well documented but rarely fixed. Most organizations treat each problem in isolation, buy a tool, and wait for adoption that never comes.
This blog names nine KM challenges, explains why each happens, and gives you a concrete fix. No vague advice. Just what actually works.
Why Knowledge Management is harder than it looks
What makes KM difficult in modern organizations
Knowledge does not sit in one place. It lives in documents, email threads, Slack channels, people's heads, and the institutional memory of teams that have never written down how they actually work.
Getting all of that into a usable system requires decisions that most organizations never make explicitly. The system gets built informally, nobody owns the whole, and that is where the problems start.
What poor Knowledge Management actually costs

McKinsey research shows employees spend an average of 1.8 hours per day searching for information. Multiplied across a 200-person team, that is roughly $4.25 million in lost productivity per year from search time alone. Add the cost of repeated mistakes, slow onboarding, and decisions made on incomplete information, and the real cost of poor KM is significantly higher.
Every challenge below is a cost that compounds.
Key challenges of Knowledge Management and how to solve them
Getting leadership and employee buy-in
Why it happens
KM is easy to deprioritize. APQC research shows that 39 percent of KM experts say leaders are focused on what they see as more urgent problems, and 38 percent say organizational culture does not incentivize knowledge sharing. When KM is treated as a support function rather than a business driver, it gets underfunded and underused.
How to fix it
Frame KM in financial terms before you ask for anything. For example, a new hire taking 90 days to reach full productivity - using $75 per hour as a fully loaded cost estimate - represents significant partial productivity loss. Cut that to 60 days with structured knowledge access, and the savings per hire are material. Multiply by annual hiring volume, and the business case writes itself.
For adoption, embed the knowledge base in tools employees already use. A Slack integration that surfaces answers without switching context, or a CRM plugin during a support call, removes the friction that kills adoption.
Breaking down information silos
Why it happens
Teams build their own systems because the central system does not meet their needs. Sales has a Notion workspace. Engineering uses Confluence. Customer success keeps everything in a shared Google Drive. Each team's system works for them and fails everyone else.
How to fix it
Start by identifying the ten questions that cross team boundaries most often. Document those answers somewhere everyone can find them. You have not fixed the silo problem entirely, but you have fixed the part that causes the most friction.
For the structural fix, build a shared layer above the existing tools rather than replacing them. Teams keep what they use. The shared layer holds cross-functional answers without the political battles.
Poor content quality that breaks AI
Why it happens
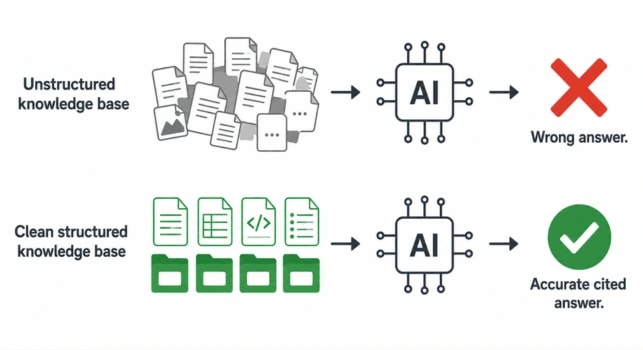
Most AI pilots fail not because the technology does not work, but because the knowledge base feeding the AI is not ready. Research shows 95 percent of enterprise AI pilots fail before delivering ROI - and the root cause is almost always poor data quality, inconsistent structure, or missing content. AI cannot surface what does not exist, and it will confidently surface what is wrong.
How to fix it
Before connecting AI, run a content audit. A clean, structured knowledge base is far more effective with AI than a large, unstructured one.
Set minimum quality standards for AI-accessible content. An article with no review date, no named owner, and no clear scope should not reach your AI layer. The model will surface it with the same confidence as a verified, current document. There is no quality signal in the output - only in the input.
Managing information overload
Why it happens
Most knowledge bases grow by addition and never by curation. Nobody deletes anything because deleting feels risky. Over time, the system becomes a graveyard of outdated content that employees stop trusting.
How to fix it
Every article needs a review date before it goes live, quarterly for fast-changing content, annually for stable content. When the date passes, and nobody responds, the article gets archived automatically rather than left live with silent errors.
Track two search metrics alongside content volume. Failed searches - queries that return no results, show you what content is missing. Low-click searches, queries with results that nobody opens - show you what content exists but is not trusted. These two signals tell you more about knowledge base health than article count ever will.
AI governance, trust, and hallucination risk
Why it happens
Generative AI produces confident, well-formed answers that can be partially or entirely wrong. The problem is not that AI is unreliable - it is that it does not signal its own uncertainty the way a colleague would.
How to fix it
Every AI-generated answer should display its source. This one design decision changes user behaviour - employees stop accepting answers passively and start verifying them. That is the right habit to build.
Define content categories where AI answers require human validation before becoming authoritative: compliance, legal, safety, and medical. Do this before you go live, not after the first hallucination causes a problem.
Keeping content reliable and up to date
Why it happens
Challenge 4 is about too much content. This is about content that exists but quietly becomes wrong. An article from two years ago looks identical to one from last week. No warning. No indication that the process changed or the product was discontinued. Employees follow outdated guidance and make avoidable mistakes.
How to fix it
Challenge 4 is about volume. This one is about accountability. Every article needs a named owner - a specific person, not a team - who is responsible for keeping that article accurate. When the review date arrives, that person gets the reminder. If they do not respond, the article gets flagged and surfaced less prominently in search until someone takes ownership.
The same pattern plays out in every industry. A dosing guide with no review date is still live after the guidance changed. One person follows it. That is not just a KM failure - it is a liability.
Securing knowledge without limiting access
Why it happens
Security and access are treated as opposites when they do not have to be. IT locks down the system, employees work around it, and that creates a different security problem.
How to fix it
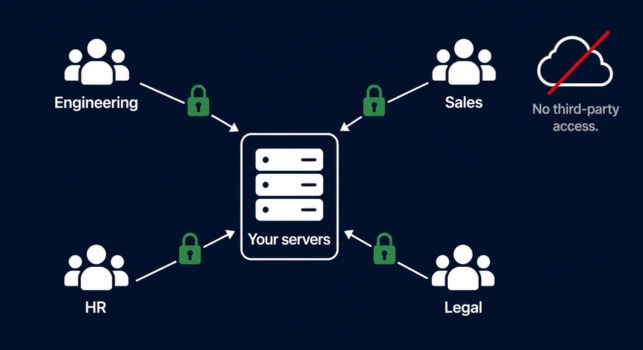
Map your content categories to your org structure and define what each role actually needs. Most access problems come from blanket permissions set at deployment and never reviewed. A quarterly access review fixes that.
The deeper question is where your data actually lives. A cloud-hosted knowledge base means your proprietary content leaves your environment. For organizations with compliance requirements or competitive sensitivity, self-hosting means your data stays on your servers, your access controls are yours, and no third party can access or train on your content.
If data residency and access control matter to your team, Accurez is a self-hosted AI knowledge base built around that requirement. Book a demo to see how it works in practice.
Get instant answers from your documents
Measuring KM impact and ROI
Why it happens
KM teams cannot demonstrate value because they never set a baseline. Without knowing the search time before the system went live, there is no way to prove what changed after.
How to fix it
Start with three metrics: search success rate, time-to-answer, and content freshness. Tracked consistently, these three numbers give you the data to defend the KM budget in any conversation.
Survey 20 to 30 employees on daily search time before implementation. Track escalation volume. Six months after launch, repeat the survey. The difference multiplied by hourly cost and headcount is your ROI number.
Scaling KM across the enterprise
Why it happens
What works for 50 people breaks at 500. Organizations that do not redesign their KM model as they grow end up with an enterprise-sized mess instead of an enterprise-grade system.
How to fix it
Enterprise-scale KM requires a federated ownership model. This is different from article-level ownership. The central team owns standards and governance. Department owners, one per major domain, are accountable for the entire body of content in their area: what gets created, what gets reviewed, and what gets retired. Without this split, the central team gets overwhelmed, and quality collapses under volume.
Define your taxonomy before the content volume makes retrofitting painful. A document tagged as 'sales-process' in one team and 'sales process' in another breaks cross-functional search silently. Set standards early, enforce them consistently.
Conclusion
The challenges of knowledge management are predictable and solvable. The organizations that get this right name an owner for every piece of content, set a baseline before they start, and build the system around how employees actually work.
Start with the challenge that costs the most right now. Fix it, measure it, then move to the next.
Accurez is an AI knowledge base software that gives your team full control over content, access settings, and data - all hosted on your own servers. If you want to see how it handles the challenges covered in this blog, book a demo, and we will walk you through it.

Mohamed Nizamudeen
Mohamed Nizamudeen writes about AI and knowledge management, with a focus on RAG systems and how businesses use them to build smarter knowledge bases. He writes for business owners and product teams who want to understand how modern knowledge bases work and how to get the most out of them.
Get instant answers from your documents

Get early access to Accurez
We are opening access to a limited number of teams before public launch.
